Bonjour,
Ouverture de ce mini-blog intitulé "ProG" (prononcer "projet" ou "prog" diminutif de programmation).
On commence avec le projet du Scrabble.
Je vais fournir ici une première base. En principe pas sûr que vous trouviez sur internet car c'est une application méthodologique que j'ai imaginé (mais probablement courante), celle de la "super suite".
///
ILLUSTRATION
A 1
B 2
C 4
D 8
E 16
F 32
G 64
H 128
I 256
J 512
K 1024
L 2048
M 5096
N 10192
O 20384
P 40768
Q 81536
R 163 072
S 326 144
T 652 288
U 1 304 576
V 2 609 152
W 5 218 304
X 10 436 608
Y 20 873 216
Z 41 746 432
ORDINATEUR
(20384+163072+8+256+10192+1+652288+16+1304576+163072) = 2 313 865
HUMAINS
(128+1304576+5096+1+256+10192+326144) = 1 646 393
Explication vocale :
https://voca.ro/1cmylsMvqrkk
Pour être notifié de nouveaux messages, entrer dans un forum puis cliquer sur "S'abonner au forum" (+ infos)
Blog : ProG
Re: Blog : ProG
Bonjour,
Suite des opérations.
Précédemment, nous avons vu que la "super suite" permet d'éviter d'avoir à tester toutes les possibilités pour un tirage aléatoire de 7 lettres, ce qui représenterait (1*2*3*4*5*6*7) 5040 possibilités, que l'on ne testera pas.
A la place je voulais réaliser un système d'indexage, cependant il y a des cas de figure où les adresses ne renverront vers "rien" et dans ce cas il faut mettre en place une routine qui testera toutes les combinaisons possibles de la super suite.
C'est du simple calcul combinatoire (sans permutation, donc, grâce à la super suite appliquée) pour une ligne qu'on appellera (A, B, C, D, E, F, G) :
- Pour 1 tirage de 7 lettres si je prends 7 lettres cela donne 1 combinaison possible.
- Pour 6 lettres si je prends 6 cela donne :
(illustration pour exemple)
A,B,C,D,E,F
A,B,C,D,E,G
A,B,C,D,F,G
A,B,C,E,F,G
A,B,D,E,F,G
A,C,D,E,F,G
B,C,D,E,F,G
= 7 combinaisons possibles
- Pour 5 lettres cela donne 21 combinaisons
- Pour 4 lettres cela donne 35 combinaisons
- Pour 3 lettres 35
- Pour 2 lettres 21
Ajouté 7 au résultat dans le cas d'1 lettre car chaque lettre unique peut être indépendamment ajoutée sur le plateau.
Donc nous avons en définitif (1+7+21+35+35+21) 120 possibilités qui représenteront surtout l'adresse du(des) mot(s) possible(s) à aller trouver.
Donc, très simplement, nous venons de voir que la recherche combinatoire ajoutée à la méthode de la super suite réduit drastiquement le nombre d'itération à réaliser, on passe de 5040 possibilités à 120... en terme de "temps machine" (relatif selon la puissance machine évidemment) c'est une fraction de seconde.
Petit complément vocal :
https://voca.ro/1ensPzdlzgvE
Suite des opérations.
Précédemment, nous avons vu que la "super suite" permet d'éviter d'avoir à tester toutes les possibilités pour un tirage aléatoire de 7 lettres, ce qui représenterait (1*2*3*4*5*6*7) 5040 possibilités, que l'on ne testera pas.
A la place je voulais réaliser un système d'indexage, cependant il y a des cas de figure où les adresses ne renverront vers "rien" et dans ce cas il faut mettre en place une routine qui testera toutes les combinaisons possibles de la super suite.
C'est du simple calcul combinatoire (sans permutation, donc, grâce à la super suite appliquée) pour une ligne qu'on appellera (A, B, C, D, E, F, G) :
- Pour 1 tirage de 7 lettres si je prends 7 lettres cela donne 1 combinaison possible.
- Pour 6 lettres si je prends 6 cela donne :
(illustration pour exemple)
A,B,C,D,E,F
A,B,C,D,E,G
A,B,C,D,F,G
A,B,C,E,F,G
A,B,D,E,F,G
A,C,D,E,F,G
B,C,D,E,F,G
= 7 combinaisons possibles
- Pour 5 lettres cela donne 21 combinaisons
- Pour 4 lettres cela donne 35 combinaisons
- Pour 3 lettres 35
- Pour 2 lettres 21
Ajouté 7 au résultat dans le cas d'1 lettre car chaque lettre unique peut être indépendamment ajoutée sur le plateau.
Donc nous avons en définitif (1+7+21+35+35+21) 120 possibilités qui représenteront surtout l'adresse du(des) mot(s) possible(s) à aller trouver.
Donc, très simplement, nous venons de voir que la recherche combinatoire ajoutée à la méthode de la super suite réduit drastiquement le nombre d'itération à réaliser, on passe de 5040 possibilités à 120... en terme de "temps machine" (relatif selon la puissance machine évidemment) c'est une fraction de seconde.
Petit complément vocal :
https://voca.ro/1ensPzdlzgvE
Re: Blog : ProG
Bonjour,
Le module "discriminatoire" est contre-productif donc n'est pas retenu.
Mais j'ai trouvé l'idée d'une structure de base de données contenant tous les mots qui permet(trait) de se passer de la méthode de la super suite.
Cependant, on en revient au débat "lecture disque" versus "opérations" (pour simplifier) et la seule façon de trancher est de développer les deux méthodes en parallèle pour les expérimenter et les comparer (sur le même matériel) en fonctionnement. Pour trouver la meilleure solution, c'est très concret... il faut faire.
Mais donc, pour chaque solution, il faut une base de données des mots qui lui soit propre.
La méthode qui supplante le test des 120 combinaisons demande une structure à la fois spécifique mais on ne peut plus simple.
Il s'agit d'une structure arborescente ou chaque lettre constituant les "400 000" mots se trouve être le nom propre à chaque répertoire renvoyant sur les possibilités des lettres suivantes. Je présenterai à venir le schéma des deux méthodes.
La seconde méthode n'est pas si contraignante.
De plus, la base de données contenant tous les mots devrait être "plus légère" que celle de la super suite, car chaque lettre sera potentiellement occupée pour plusieurs mots.
Je suis conscient qu'en l'état, il n'est sans-doute pas possible de "visualiser" la solution. Des schémas arriveront prochainement.
Pour autant, même si cette nouvelle méthode rendrait dispensable "la super suite", cette dernière n'est pas à écarter. De plus, il ne m'est pas possible de me prononcer sur "la meilleure" méthode actuellement (du côté des performances). Ca dépend du matériel, ça dépend comment c'est programmé. Vis à vis des mots "longs" (de 8 à 15 lettres) il se pourrait que la seconde méthode se démarque et tire son épingle sur les plus grandes longueurs de mots. Du coup, il deviendrait inutile (dans un premier temps) de créer une valeur numérique pour chaque lettre puisque l'adresse "répertoire" de chaque mot serait leur suite de lettres contenue dans le nom même de chaque répertoire et sous répertoire.
Ainsi, "chat" serait (par exemple) une suite de 4 répertoires, soit "c" puis un sous répertoire "h" puis sous répertoire "a" puis sous répertoire "t". Dans le répertoire "t" se trouverait un fichier nommé "." (point) simplement pour indiquer qu'ici se trouve la fin d'un mot. Pourquoi ? Parce que si nous poursuivons, selon le tirage que nous avons, on pourrait très bien poursuivre pour faire "chaton" ou "chatte", ou encore "chatière"... etc... donc la possibilité de poursuivre le "chemin" dans chaque sous-répertoire suivant, fonction des lettres restantes que nous possédons.
Nous n'avons plus aucune opération à réaliser, plus de combinaisons à faire. C'est juste de l'accès disque sans pour autant n'ouvrir aucun fichier (du moins en l'état actuel du projet). Pour un tirage de 7 lettres, je n'aurais juste qu'à tester l'existence de 7 suites qui pourrait aller au total jusqu'à 49 répertoires maximum (dans cette configuration) mais c'est théorique. En pratique, le test stopperait bien avant... car jamais il n'y a 7 scrabbles différents pour une suite de 7 lettres. Bien sûr, ici je ne considère pas les mots les plus longs, mais ils seront bien présents et c'est une question qui sera soulevée en son heure.
Merci.
Le module "discriminatoire" est contre-productif donc n'est pas retenu.
Mais j'ai trouvé l'idée d'une structure de base de données contenant tous les mots qui permet(trait) de se passer de la méthode de la super suite.
Cependant, on en revient au débat "lecture disque" versus "opérations" (pour simplifier) et la seule façon de trancher est de développer les deux méthodes en parallèle pour les expérimenter et les comparer (sur le même matériel) en fonctionnement. Pour trouver la meilleure solution, c'est très concret... il faut faire.
Mais donc, pour chaque solution, il faut une base de données des mots qui lui soit propre.
La méthode qui supplante le test des 120 combinaisons demande une structure à la fois spécifique mais on ne peut plus simple.
Il s'agit d'une structure arborescente ou chaque lettre constituant les "400 000" mots se trouve être le nom propre à chaque répertoire renvoyant sur les possibilités des lettres suivantes. Je présenterai à venir le schéma des deux méthodes.
La seconde méthode n'est pas si contraignante.
De plus, la base de données contenant tous les mots devrait être "plus légère" que celle de la super suite, car chaque lettre sera potentiellement occupée pour plusieurs mots.
Je suis conscient qu'en l'état, il n'est sans-doute pas possible de "visualiser" la solution. Des schémas arriveront prochainement.
Pour autant, même si cette nouvelle méthode rendrait dispensable "la super suite", cette dernière n'est pas à écarter. De plus, il ne m'est pas possible de me prononcer sur "la meilleure" méthode actuellement (du côté des performances). Ca dépend du matériel, ça dépend comment c'est programmé. Vis à vis des mots "longs" (de 8 à 15 lettres) il se pourrait que la seconde méthode se démarque et tire son épingle sur les plus grandes longueurs de mots. Du coup, il deviendrait inutile (dans un premier temps) de créer une valeur numérique pour chaque lettre puisque l'adresse "répertoire" de chaque mot serait leur suite de lettres contenue dans le nom même de chaque répertoire et sous répertoire.
Ainsi, "chat" serait (par exemple) une suite de 4 répertoires, soit "c" puis un sous répertoire "h" puis sous répertoire "a" puis sous répertoire "t". Dans le répertoire "t" se trouverait un fichier nommé "." (point) simplement pour indiquer qu'ici se trouve la fin d'un mot. Pourquoi ? Parce que si nous poursuivons, selon le tirage que nous avons, on pourrait très bien poursuivre pour faire "chaton" ou "chatte", ou encore "chatière"... etc... donc la possibilité de poursuivre le "chemin" dans chaque sous-répertoire suivant, fonction des lettres restantes que nous possédons.
Nous n'avons plus aucune opération à réaliser, plus de combinaisons à faire. C'est juste de l'accès disque sans pour autant n'ouvrir aucun fichier (du moins en l'état actuel du projet). Pour un tirage de 7 lettres, je n'aurais juste qu'à tester l'existence de 7 suites qui pourrait aller au total jusqu'à 49 répertoires maximum (dans cette configuration) mais c'est théorique. En pratique, le test stopperait bien avant... car jamais il n'y a 7 scrabbles différents pour une suite de 7 lettres. Bien sûr, ici je ne considère pas les mots les plus longs, mais ils seront bien présents et c'est une question qui sera soulevée en son heure.
Merci.
Re: Blog : ProG
Pour illustrer mon propos précédent, j'ai mené quelques recherches et j'ai pu trouver la technique qui en effet existe et c'est même ainsi que l'on crée les dictionnaires numériques (comme quoi "imaginer" ne signifie pas "inventer", mais quand on imagine des méthodes qui existent : c'est bon signe !) :
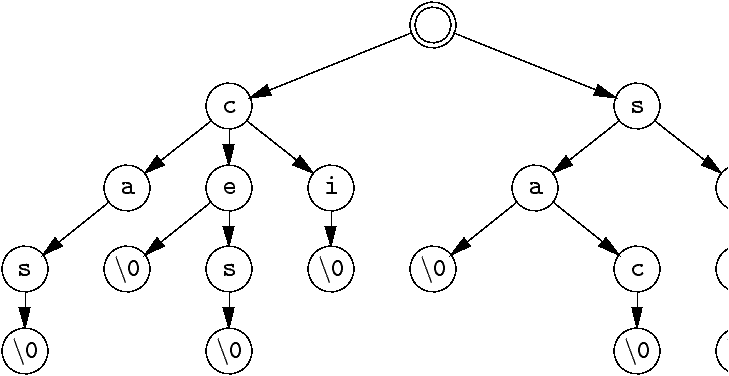
Source : http://pauillac.inria.fr/~maranget/X/421/08/cours.html
Voyez pour cet exemple on trouve les mots : cas, ce, ces, ci (mon fameux "." point est ici représenté par "\0" pour signifier un mot complet),
et de l'autre côté : sa, sac, etc...
Absolument tous les + de 400 000 mots peuvent être intégrés sous la forme de 26 "ensembles" (ou arbres), chaque ensemble étant chacune des lettres alphabétiques.
Cette méthode permet de gros avantages.
Déjà, un gain de place puisque chaque lettre peut-être utilisée pour constituer plusieurs mots, comme on le voit sur le schéma.
Puis, cela facilite grandement la recherche de mots. Dans le cas où il faudrait trouver tous les mots possibles et existants au sein d'un tirage de lettres aléatoires, l'algorithme de lecture d'une telle arborescence de lettres pour trouver les mots est on ne peut plus simple.
Néanmoins, cela n'enlève pas l'intérêt pour la méthode de la super suite, dont les adresses générées par incrémentations pourraient contenir les mots possibles sous la forme de tels arbres (constitués simplement de répertoires/sous-répertoires/sous-sous-répertoires... etc...), il est donc toujours possible de mixer les deux techniques pour répondre à un besoin spécifique.
Source : http://pauillac.inria.fr/~maranget/X/421/08/cours.html
Voyez pour cet exemple on trouve les mots : cas, ce, ces, ci (mon fameux "." point est ici représenté par "\0" pour signifier un mot complet),
et de l'autre côté : sa, sac, etc...
Absolument tous les + de 400 000 mots peuvent être intégrés sous la forme de 26 "ensembles" (ou arbres), chaque ensemble étant chacune des lettres alphabétiques.
Cette méthode permet de gros avantages.
Déjà, un gain de place puisque chaque lettre peut-être utilisée pour constituer plusieurs mots, comme on le voit sur le schéma.
Puis, cela facilite grandement la recherche de mots. Dans le cas où il faudrait trouver tous les mots possibles et existants au sein d'un tirage de lettres aléatoires, l'algorithme de lecture d'une telle arborescence de lettres pour trouver les mots est on ne peut plus simple.
Néanmoins, cela n'enlève pas l'intérêt pour la méthode de la super suite, dont les adresses générées par incrémentations pourraient contenir les mots possibles sous la forme de tels arbres (constitués simplement de répertoires/sous-répertoires/sous-sous-répertoires... etc...), il est donc toujours possible de mixer les deux techniques pour répondre à un besoin spécifique.